Overview
RAG Configurator is a full-stack platform that lets you design, deploy, and test custom RAG pipelines entirely through a browser UI. Pick your LLM provider, choose your retrieval strategy, configure your agent architecture, ingest documents, and start chatting — all from a 9-step visual wizard.
No boilerplate. No infrastructure wrestling. Configure, ingest, query.
The Problem
Every team building a RAG system faces the same decisions: which LLM provider, how to chunk documents, what retrieval strategy, which agent architecture. These choices are interdependent, hard to compare, and require writing significant boilerplate just to experiment. This platform removes that friction — make all choices visually, ingest your documents, test immediately, iterate.
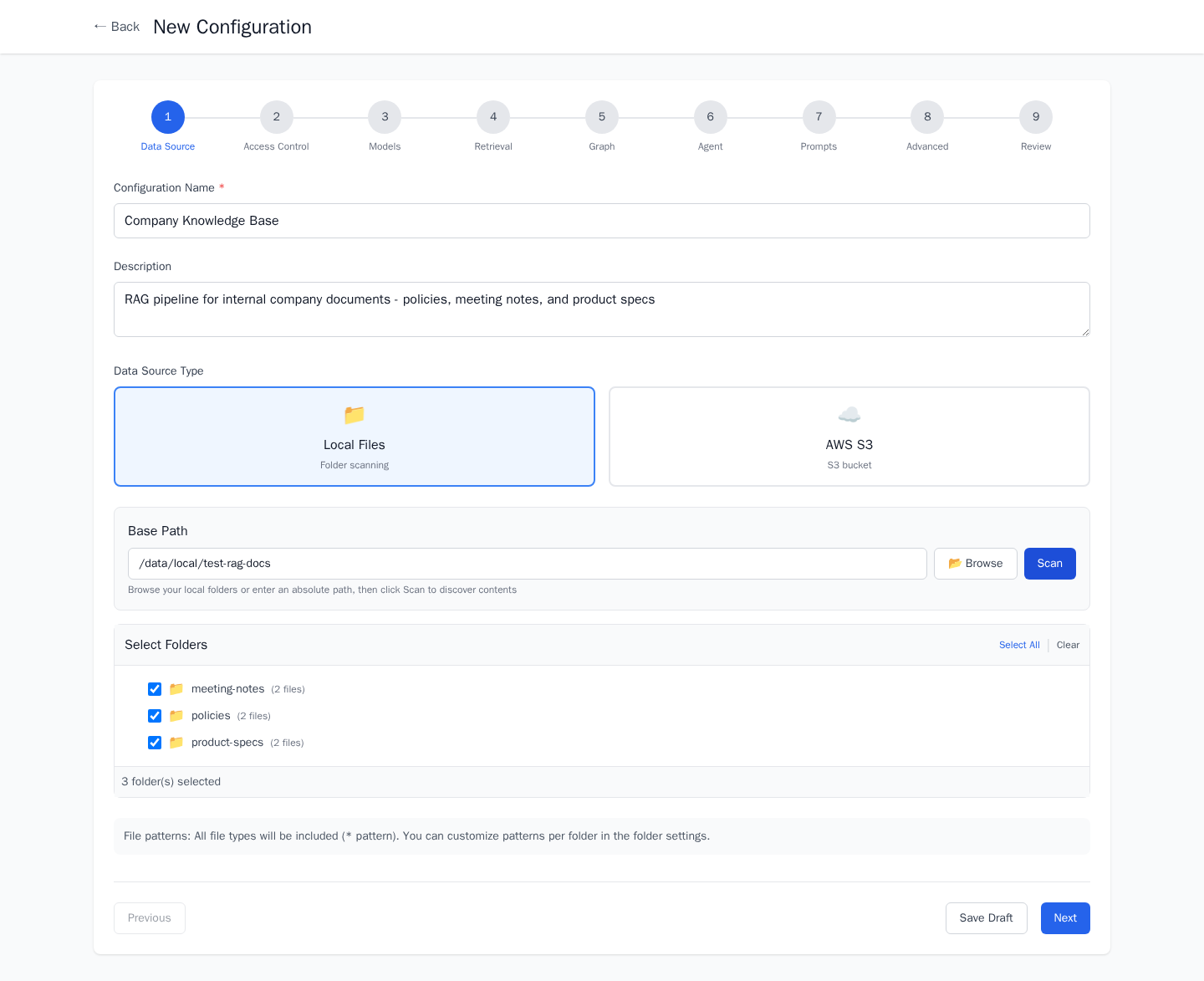
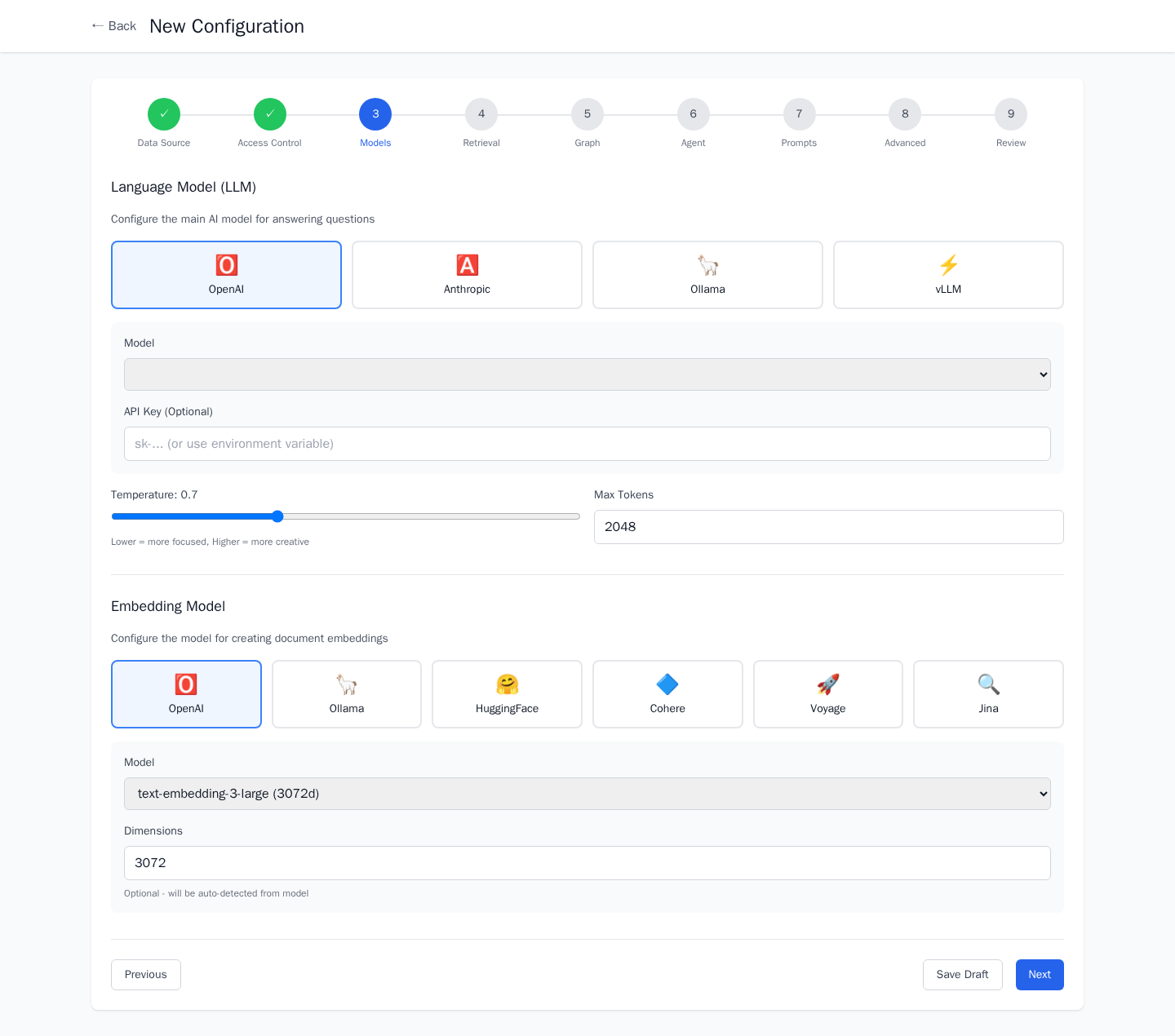
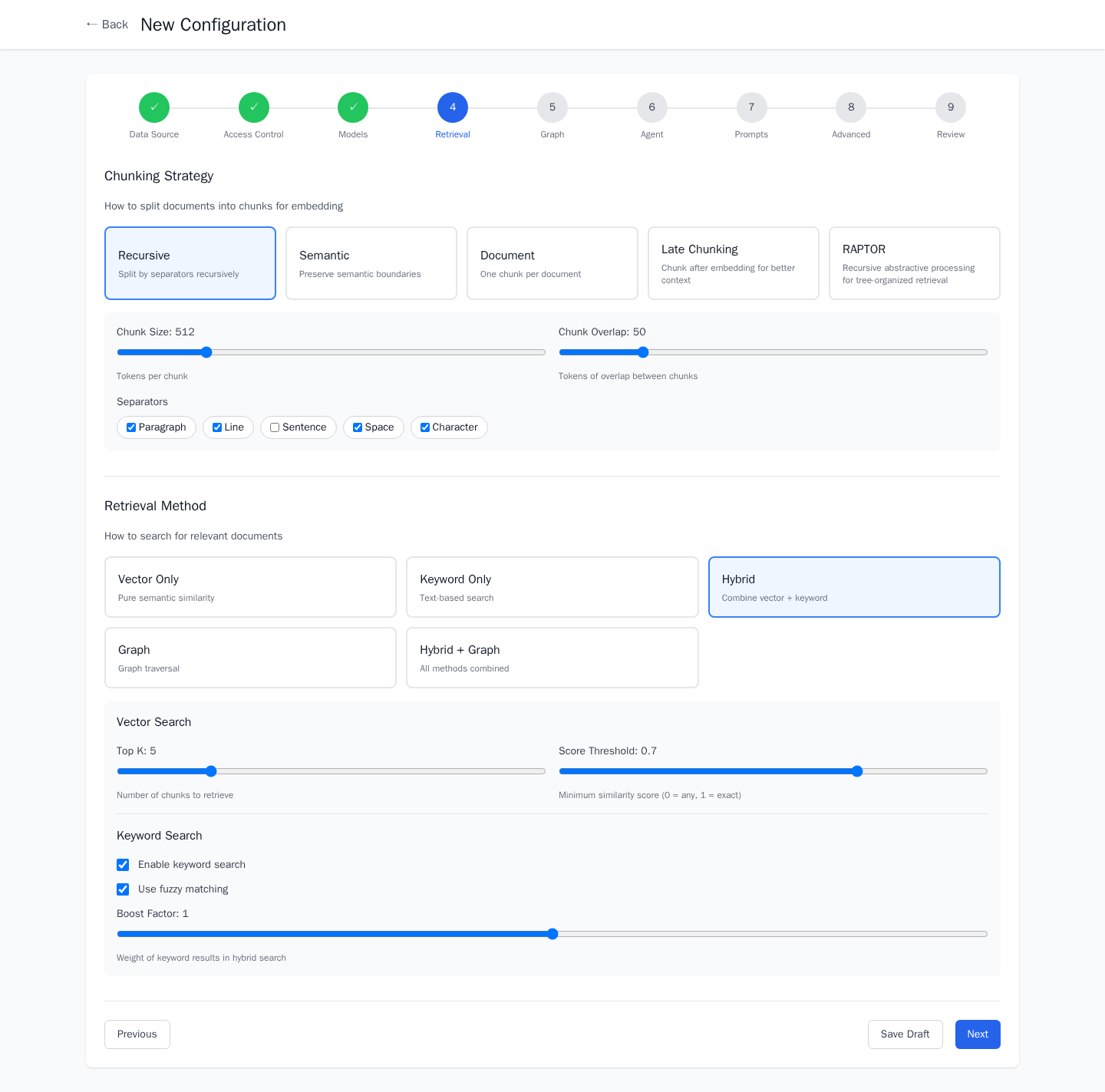
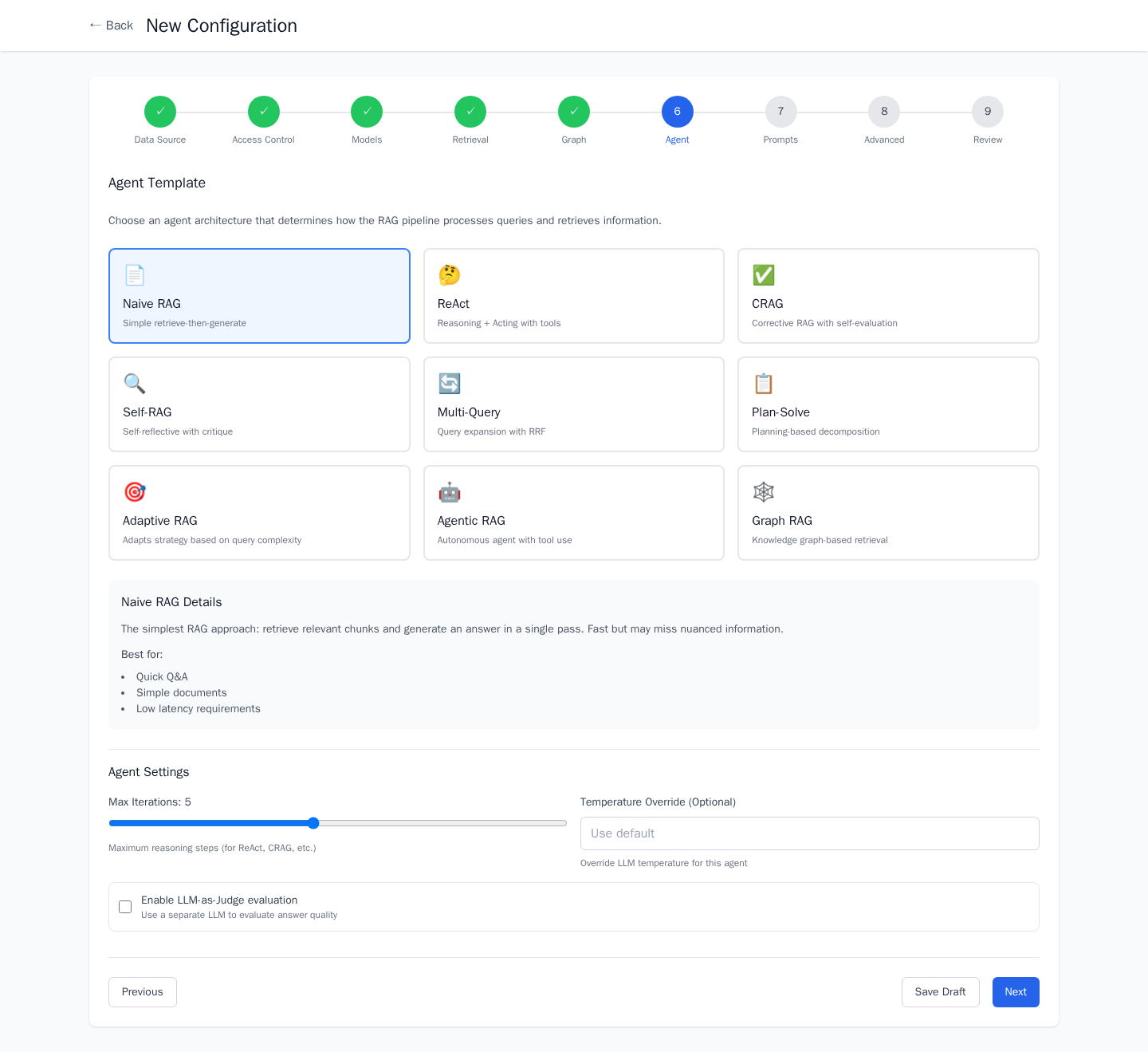
The Configuration Wizard
A 9-step wizard walks through every decision in a RAG pipeline:
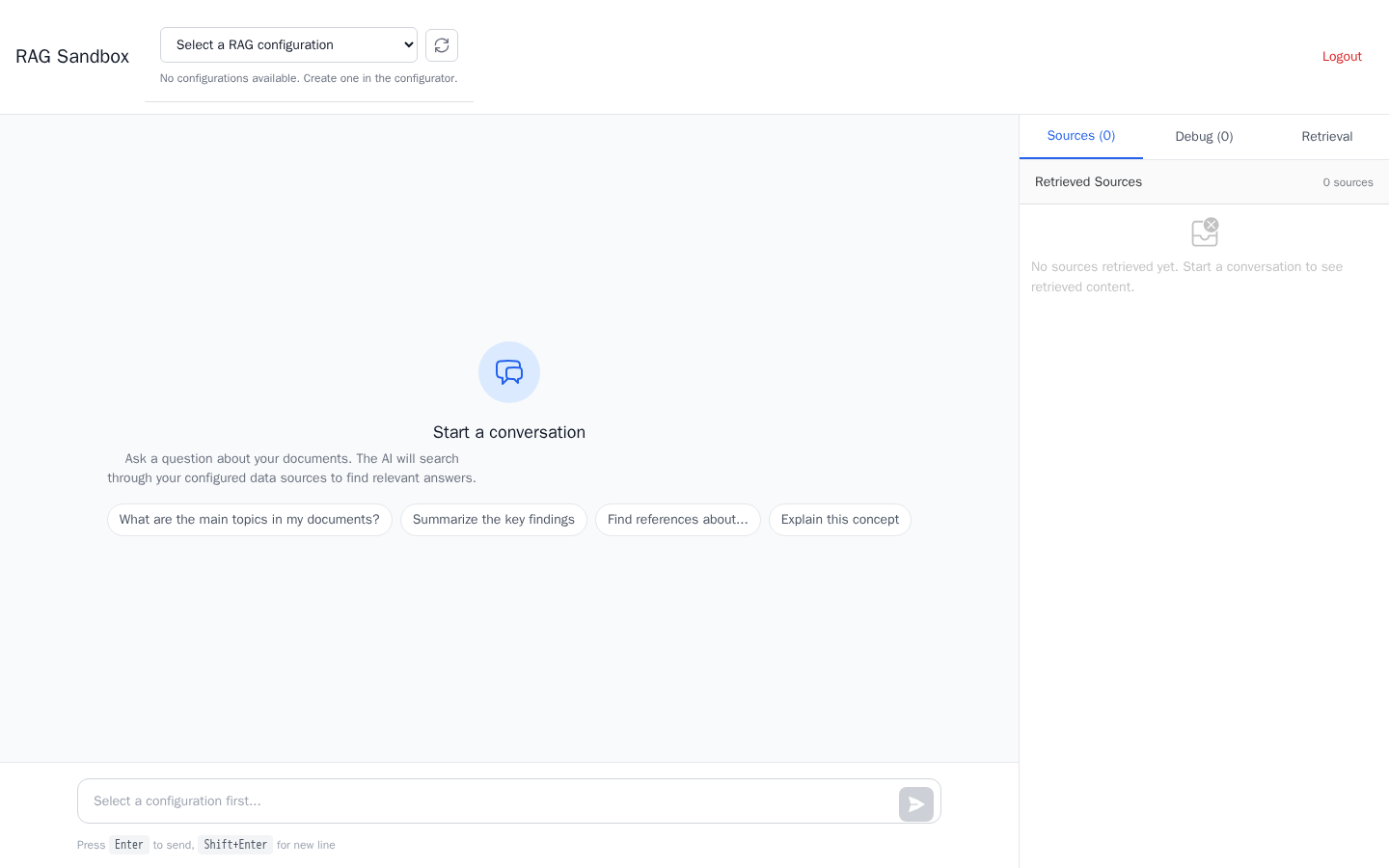
The Sandbox
Once configured and documents ingested, switch to the Sandbox UI to chat with your knowledge base. Real-time SSE streaming, retrieved source chunks with relevance scores, and a full debug panel for inspecting the retrieval pipeline.
Architecture
Four microservices behind a Go reverse proxy gateway, two Vue 3 frontends, MongoDB + Redis infrastructure:
Client → Gateway (Go/Gin :8000) → Config Service (FastAPI :8001)
→ Ingestion Service (FastAPI+Celery :8002)
→ RAG Service (FastAPI+LangGraph :8003)
Go Gateway — JWT validation, rate limiting, CORS, HMAC inter-service signing, SSE streaming passthrough. Low memory footprint, fast cold starts.
Config Service — User auth with JWT + token blacklist, pipeline configuration CRUD, folder browsing, YAML/JSON export-import.
Ingestion Service — Factory-pattern document processors (PDF via Docling, DOCX, TXT, MD, HTML, images with OCR), chunkers, and embedders. Celery workers with live progress tracking.
RAG Service — LangGraph for stateful agent orchestration across 9 agent types, 5 retrieval strategies, 4 LLM providers. Includes RAGAS evaluation, guardrails, and query caching.
Agent Architectures
| Agent | How It Works | Best For |
|---|---|---|
| Naive RAG | Retrieve → Generate | Quick Q&A, simple documents |
| ReAct | Reasoning + Acting loop with tool use | Complex queries needing iteration |
| CRAG | Evaluates retrieval quality, self-corrects | When retrieval accuracy matters |
| Self-RAG | Generates, critiques, refines iteratively | High-quality answers |
| Multi-Query | Expands query into multiple perspectives | Ambiguous or broad questions |
| Plan-Solve | Decomposes into sub-tasks, solves step-by-step | Multi-hop reasoning |
| Adaptive RAG | Selects strategy based on query complexity | Mixed workloads |
| Agentic RAG | Autonomous agent with tool use | Open-ended exploration |
| Graph RAG | Knowledge graph-based retrieval | Connected, relational data |
Tech Stack
| Layer | Technologies |
|---|---|
| Gateway | Go 1.24, Gin, golang-jwt |
| Backend | Python 3.11, FastAPI, LangGraph, Celery, Motor |
| Frontend | Vue 3, TypeScript, Vite, Tailwind CSS, Pinia |
| Database | MongoDB 7.0 (document + vector store) |
| Cache | Redis 7 (task queue + embedding/query cache) |
| AI/ML | LangChain, OpenAI, Anthropic, Ollama, sentence-transformers |
| Infra | Docker Compose (11 containers), Nginx |
| Observability | Langfuse, OpenTelemetry |
Running Locally
Full local operation with Ollama — no cloud API keys required:
ollama pull qwen3:4b
ollama pull nomic-embed-text
docker compose up -d
Tested with qwen3:4b on an NVIDIA RTX 4050. Query latency averages 2-5 seconds depending on agent architecture.